
Our website uses cookies to enhance your browsing experience.

The article concerns the task of developing a program tool called static analyzer. The tool being developed is used for diagnosing potentially unsafe syntactic structures of C++ from the viewpoint of porting program code on 64-bit systems. Here we focus not on the problems of porting occurring in programs, but on the peculiarities of creating a specialized code analyzer. The analyzer is intended for working with the code of C/C++ programs.
One of the modern tendencies in IT is port of software on 64-bit processors. Obsolete 32-bit processors (and consequently 32-bit programs) have some limitations which impede software developers and hold back the progress. First of all, such a limitation is the size of the maximum available main memory for a program (2 GB). Although there are some methods which allow you to evade these limitations in some cases, in general we can for sure say that port on 64-bit program solutions is inevitable.
For most programs porting on a new architecture means at least the necessity of their recompilation. Of course, there can be other ways. But within the framework of this article we speak about C and C++ languages that's why recompilation is inevitable. Unfortunately, this very recompilation often has unexpected and unpleasant consequences.
Change of the architecture's capacity (for example from 32 bits to 64 bits) means, first of all, change of the sizes of the basic data types and also correlations between them. As the result behaviour of a program can change after its recompilation for a new architecture. Practice shows that the behavior is not only able to change but it really does. And the compiler very often doesn't show warning messages on those constructions which are potentially unsafe from the viewpoint of the new 64-bit architecture. Of course, less correct code sections will be detected by the compiler. However, far not all the potentially unsafe syntactic constructions can be detected with the help of the traditional program tools. And it is this reason that a new code analyzer appears. But before we speak about the new tool we still need to describe the errors, which our analyzer will detect, in detail.
Detailed analysis of all the potentially unsafe C and C++ syntactic constructions is beyond the scope of this article. We refer those readers who are interested in this problem to the encyclopaedic article [1] which gives rather full investigation of this issue. For purposes of projecting a code analyzer we still should list the main types of errors here.
Before we speak about concrete errors let's revise some data types used in C and C++ languages. They are listed in Table 1.
|
Type name |
Type size in bits (32-bit system) |
Type size in bits (64-bit system) |
Description |
|---|---|---|---|
|
ptrdiff_t |
32 |
64 |
Signed integer type resulting from subtraction of two pointers. Basically used for storing sizes and indexes of arrays. Sometimes is used as the result of the function returning the size or -1 when an error occurs. |
|
size_t |
32 |
64 |
Unsigned integer type. The result of sizeof() operator. Often used for storing size or number of objects. |
|
intptr_t, uintptr_t, SIZE_T, SSIZE_T, INT_PTR, DWORD_PTR etc |
32 |
64 |
Integer types capable to store a pointer's value. |
Table N1. Description of some integer types.
What is peculiar about these data types is that their size alters depending on the architecture. On 64-bit systems it is 64 bits and on 32-bit ones - 32 bits.
Let's introduce the notion "memsize-type":
DEFINITON: By memsize-type we understand any simple integer type able to store a pointer and changing its size when the paltform's capacity changes from 32-bit to 64-bit. All the types listed in table 1 are memsize-types.
Most problems occurring in the code of programs (if we speak about support of 64 bits) relate to disuse or incorrect use of memsize-types.
So, let's describe the possible errors.
Presence of "magic" constants (i.e. values calculated in an unknown way) in programs is in itself undesirable. But in case of porting programs on 64-bit systems "magic" constants acquire one more very significant disadvantage. They can lead to incorrect operation of programs. We speak about those "magic" constants which focus on some concrete peculiarity of the architecture. For example, they may focus on that the size of a pointer is 32 bits (4 bytes).
Let's consider a simple example.
size_t values[ARRAY_SIZE];
memset(values, ARRAY_SIZE * 4, 0);On a 32-bit system this code would be correct but the size of size_t type on a 64-bit system increases to 8 bytes. Unfortunately, a fixed size (4 bytes) was used in the code. As the result the array will be filled with zeros not completely.
There are some other variants of incorrect use of such constants.
Let's consider an example of a type error in address arithmetic
unsigned short a16, b16, c16;
char *pointer;
...
pointer += a16 * b16 * c16;This example works correctly with pointers if the value of "a16 * b16 * c16" expression doesn't exceed UINT_MAX (4Gb). This code could always work correctly on a 32-bit platform as the program never allocated arrays of more size. On a 64-bit architecture the array's size exceeded UINT_MAX items. Suppose, we want to shift the pointer's value at 6.000.000.000 bytes, so variables a16, b16 and c16 have values 3000, 2000 and 1000 correspondingly. When calculating "a16 * b16 * c16" expression all the variables will be converted into int type according to C++ rules and only after that they will be multiplied. During multiplication an overflow will occur. The incorrect result of the expression will be extended to ptrdiff_t type and incorrect calculation of the pointer will occur.
But such errors occur not only by large data but in common arrays as well. Let's consider an interesting code for working with an array containing only 5 items. This example works in 32-bit mode but it won't work in 64-bit mode:
int A = -2;
unsigned B = 1;
int array[5] = { 1, 2, 3, 4, 5 };
int *ptr = array + 3;
ptr = ptr + (A + B); //Invalid pointer value on 64-bit platform
printf("%i\n", *ptr); //Access violation on 64-bit platformLet's follow the process of calculating "ptr + (A + B)":
After that "ptr + 0xFFFFFFFFu" expression is calculated but the result will depend on the on the size of the pointer on the given architecture. If addition is performed in a 32-bit program this expression will be similar to "ptr - 1" and we'll successfully print number 3.
In a 64-bit program 0xFFFFFFFFu value will be fairly added to the pointer and consequently the pointer will be far outside the array's limits. And when we try to get access to the item by this pointer we'll meet troubles.
Using memsize- and non-memsize-types in expressions can lead to incorrect results on 64-bit systems and relate to changing of the input values' range. Here are some examples:
size_t Count = BigValue;
for (unsigned Index = 0; Index != Count; ++Index)
{ ... }This is an example of an eternal loop if Count > UINT_MAX. Suppose on 32-bit systems this code worked with the range of less than UINT_MAX iterations. But the 64-bit version of the program can process more data and it may need more iterations. As values of Index variable lie within the range [0..UINT_MAX] the condition "Index != Count" will never be fulfilled and that will lead to the eternal loop.
If you have large hierachies of inheritance of classes with virual functions in your program, you can inadvertently use arguments of different types which actually coincide on a 32-bit system. For example, in the basic class you use size_t type as the argument of a virtual function while in the child class you use unsigned type. Consequnetly, this code will be incorrect on a 64-bit system.
This error doesn't necessarily lie in complex heritage hierachies and here is an example:
class CWinApp {
...
virtual void WinHelp(DWORD_PTR dwData, UINT nCmd);
};
class CSampleApp : public CWinApp {
...
virtual void WinHelp(DWORD dwData, UINT nCmd);
};You'll face troubles when compiling this code for a 64-bit platform. You'll get two functions with the same name but with different parameters and the user's code will fail to launch as the result.
Similar problems can occur when using overloaded functions.
As we've already said this is far not the complete list of possible errors (see [1]), however, it allows you to formulate requirements to the code analyzer.
On the basis of the list of potentially unsafe constructions which need to be diagnosed we can formulate the following requirements:
We should mention that the concrete architecture of implementing the listed functional doesn't matter, but this implementation must be full.
In the literature on developing compilers [2] it is said that the traditional compiler has the following operation stages:
Figure 1 - A traditional compiler's operation stages
Pay attention that these are "logical" operation phases. In the real compiler some stages are united and some are executed parallel with the others. Thus, for example, phases of syntactic and semantic analyses are combined.
Neither code generation nor its optimization is needed for the code analyzer. That is, we must develop the part of the compiler which performs lexical, syntactic and semantic analysis.
On the basis of the listed requirements to the system being developed, we can offer the following structure of the code analyzer:
The listed units are standard [4] for traditional compilers (figure 2), or more exactly for that part of the compiler which is called the front end compiler.
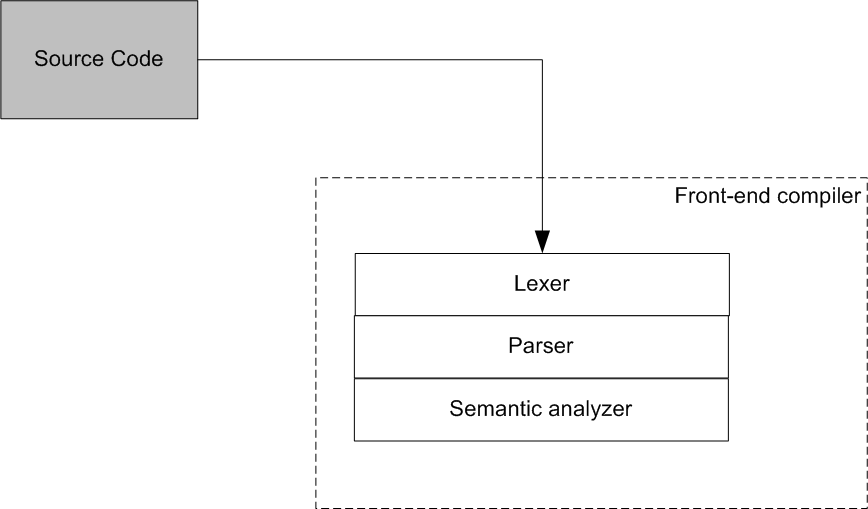
Figure 2 - Scheme of the front-end compiler
Another part of a traditional compiler - the back-end compiler - is responsible for optimization and code generation and is of no interest for us here.
Thus, the code analyzer being developed must contain the front-end compiler to provide the necessary level of code analysis.
The lexical analyzer is a finite-state machine describing the rules of lexical analysis of a concrete programming language.
Description of the lexical analyzer can be presented not only as a finitie-state machine but as a regular expression as well. Both variants of description are equal as they are easily converted into each other. Figure 3 shows the part of the finitie-state machine describing the C analyzer.
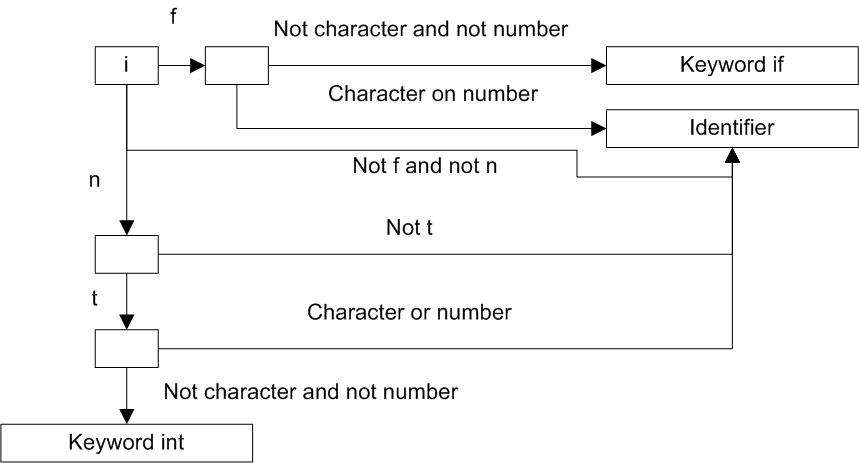
Figure 3 - The finite-state machine describing a part of the lexical analyzer (taken from [3])
As we have already said, at this stage only analysis of one type of potentially unsafe constructions is possible - use of "magic" constants. All the other types of analysis will be performed at the next stages.
The syntactic analysis unit works with the grammar apparatus to build an abstract syntax tree according to the set of lexemes got at the previous stage. The task of syntactic analysis can be formulated more exactly: can the program code be deduced from the grammar of the given lanugage? As the result of the deducibility check we get the abstract syntax tree but the point is in the very check of the code's belonging to a concrete programming language.
The code parsing results in building a parse tree. An example of such a tree for a code section is shown on figure 4.
int main()
{
int a = 2;
int b = a + 3;
printf("%d", b);
}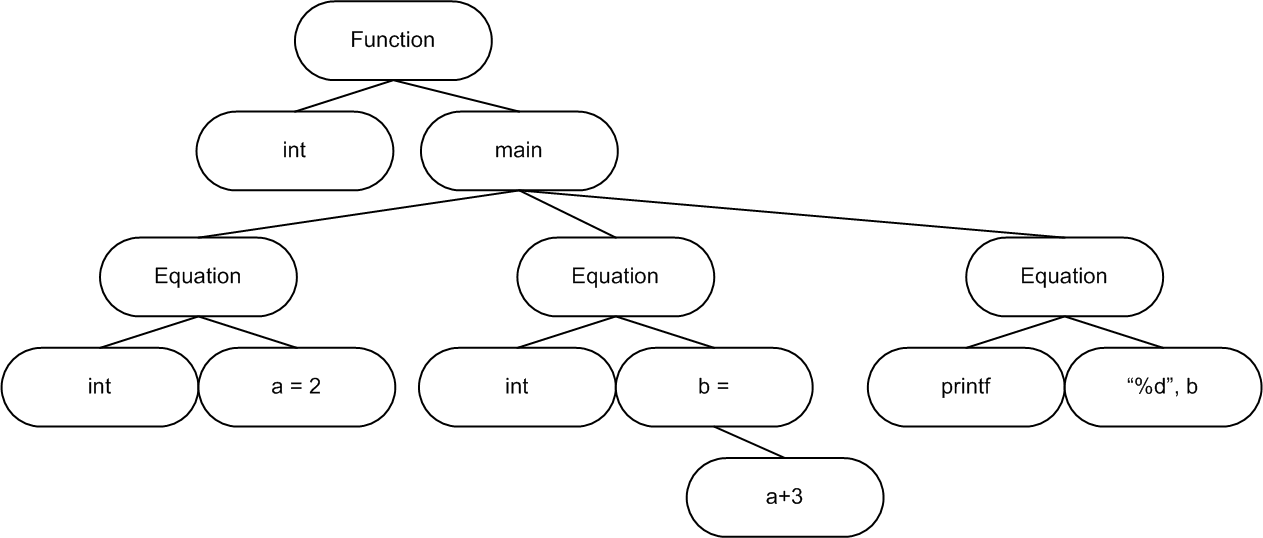
Figure 4 - Example of a parse tree
We should mention that in case of some simple programming languages the structure of a program becomes absolutely clear when the parse tree is built. But for such a complex language as C++ we need an additional stage when the built tree will be supplemented, for example, with information about data types.
In the semantic analysis unit, of the most interest is the subsystem of calculating types. The point is that data types in C++ are rather a complex and very extensible set of entities. Besides basic types characteristic of any programming language (integer, symbol etc) C++ has pointers to functions, templates, classes etc.
Such a complex subsystem of types doesn't allow us to perform the full analysis of a program at the stage of syntactic analysis. That's why the parse tree is input in the semantic analysis unit and then is supplemented with information about all the data types.
At this stage the operation of calculating types also takes place. C++ allows coding rather complex expressions, but very often it is not easy to identify their type. Figure 6 shows an example of code for which calculation of types is needed when transferring arguments into the function.
void call_func(double x);
int main()
{
int a = 2;
float b = 3.0;
call_func(a+b);
}In this case we need to calculate the type of the result of (a+b) expression and add information about the type to the parse tree (figure 7).
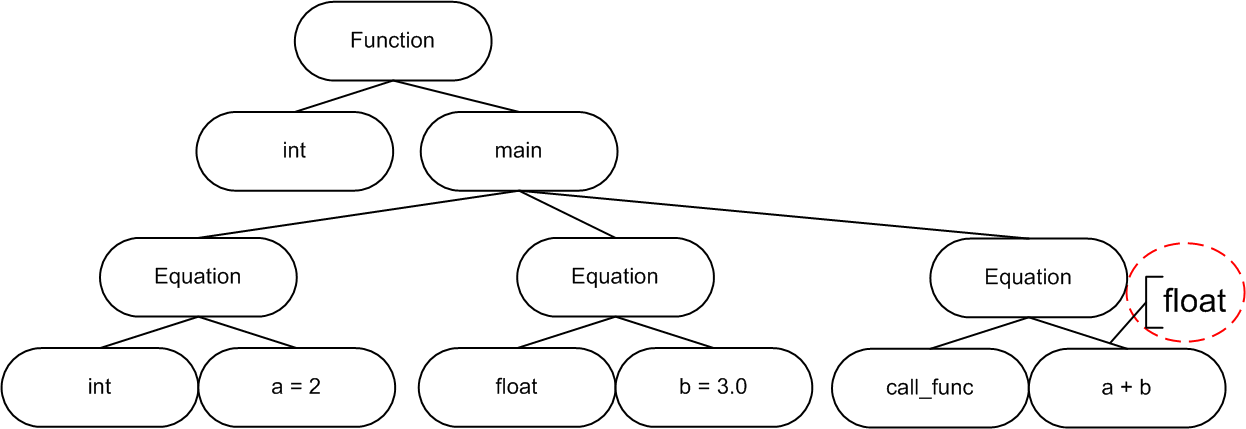
Figure 5 - Example of a parse tree supplemented with information about types
When the semantic analysis unit stops operating all possible information about the program is available for further processing.
When speaking about processing errors developers of compilers mean peuliarities of the compiler's behavior when detecting incorrect program codes. In this meaning errors can be classified into several types [2]:
All these types of errors mean that instead of a program which is correct form the programming language's viewpoint the compiler gets an incorrect program. And its task is to firstly diagnose an error and secondly continue work if possible or stop working.
A different approach to errors is used when we speak about static analysis of source program codes with the purpose of detecting potentially unsafe syntactic constructions. The basic difference lies in that the syntactic code analyzer gets program code absolutely correct lexically, syntactically and semantically. That's why it is unfortunately impossible to implement the system of diagnosing incorrect constructions in the static analyzer in the same way as the error diagnosing system in a traditional copmiler.
Implementation of the code analyzer consists in implementation of two parts:
To implement the front end compiler we will use the existing open C++ code analysis library OpenC++ [6], or more exactly its modification VivaCore [7]. This is a syntactic code analyzer written by ourselves in which analysis is performed by the recursive descendant method (recursive descendant analysis) with return. The choice of a self-written analyzer is explained by the complexity of C++ and absence of ready described grammars of this language for using aids of automatic designing of code analyzers of YACC and Bison types.
As it was said in section 3.4, to implement the subsystem of searching potentially unsafe constructions by using an error diagnosing system, which is traditional for compilers, is impossible. Let's use several methods of modifying the basic C++ grammar for this.
First of all, we need to correct the description of the basic C++ types. In section 1 we've introduced the notion of memsize-types, i.e. types of variable size (table 1). We will process all these types in programs as one special type (memsize). In other words, all the real data types important from the viewpoint of porting code on 64-bit systems, will be processed as one type in programs' code (for example, ptrdiff_t, size_t, void* etc).
Further we need to extend the grammar adding symbols-actions into its output rules [5]. Then the recursive descendant procedure which performs syntactic analysis will also perform some additional actions to check semantics. It is these additional actions that comprise the essence of the static code analyzer.
For example, a fragment of grammar for testing correctness of virtual functions (from section 1.4) can look as follows:
<HEADING_OF_VIRUTAL_FUNCTION> > <virtual> <HEADING_OF_FUNCTION> CheckVirtual()
Here CheckVirtual() is that very symbol-action. Action CheckVirtual() will be called immediately after the recursive descendant procedure has detected definition of a virtual function in the code being analyzed. And only inside the procedure CheckVirtual() arguments' correctness in defining the virtual function will be checked.
Checks of all the potentially unsafe constructions in C and C++ which are described in [1] are presented as similar symbols-actions. These symbols-actions themselves are added into the language's grammar, or more exactly, in the syntactic analyzer which calls symbols-actions when parsing the program code.
The architecture and structure of the code analyzer discussed in the article became the basis of the commercial product Viva64 [8]. Viva64 is the static analyzer of the code of the programs written in C and C++. It is intended for detecting syntactic constructions potentially unsafe from the viewpoint of porting code on 64-bit systems in the source code of programs.
Static analyzer is a program consisting of two parts:
The front end compiler is a traditional component of a common compiler, so the principles of its design and development are examined rather thoroughly.
The subsystem of diagnosing potentially unsafe syntactic constructions is that component of the static code analyzer which makes analyzers unique, differing in the set of tasks solved. Thus, within the framework of this article the task of porting the program code on 64-bit systems is discussed. It is the knowledge about 64-bit software that became the basis of the diagnosing subsystem.
Integration of the front end compiler from VivaCore project [7] and knowledge about 64-bit software [1] allowed us to develop the program product Viva64 [8].
0
0
0
0