
Our website uses cookies to enhance your browsing experience.

For a long time I was worried by some articles on the Internet in which the authors tried to judge about the usefulness of static code analyzers relying on analysis of small projects.
In many of those articles I've read their authors made the linear dependence. If static analysis detects 2 errors in a project of N lines, then it will detect only 200 errors in a project of N*100 lines. A conclusion is drawn from this that static analysis is certainly good but not great - it finds too few errors and it's better to develop other methods of bug detection.
There are two reasons why people try code analyzers on small projects. First, a large project is not that easy to check: you have to set some options, define certain data where necessary, exclude some libraries from analysis, and so on. One naturally feels reluctant to do this all. You want to check something quickly, not bother with the settings. Second, a huge number of diagnostic messages will be generated for a large project. Again, nobody wants to spend much time on checking them up. It's much easier to take a smaller project for analysis.
Consequently, one doesn't touch a large project one's currently working on and takes something small instead. For example, it can be his/her old term project or a small open-source project from GitHub.
One checks it and resorts to linear interpolation to determine how many errors can be found in his/her large project. Then one writes an article on this research.
At first sight, such researches look right and useful. But I was sure they weren't.
The first defect of all these researches is obvious. People forget that they take an already fine-tuned version of a project that works well. Many of those errors that could be found by static analysis were being searched for a long time and with great sadness - during testing or after users' complaints. That is, people forget that static analysis is a tool to be used regularly, not occasionally. Programmers study the warnings they get from their compiler every time, not once in a year, don't they?
The second defect of these researches is a bit more complicated and interesting. I had a clear feeling that small projects and large projects cannot be estimated equivalently. Suppose a student has spent 5 days to write a good term project of 1000 code lines. I'm sure he/she won't be able to write a good commercial application of 100 000 code lines in 500 days. The growing complexity will slow him/her down. As an application gets larger, it becomes harder to add new functionality into it and you need more time to test it and handle appearing errors.
So, I had that feeling but didn't know how to pose it. Suddenly one of our co-workers helped me. Studying the book "Code complete" by Steve McConnell, he noticed an interesting table there which had completely slipped my memory. This table puts everything in their places!
Of course, it is incorrect to estimate the number of errors in large projects when you deal with small ones! They have different error densities!
The larger a project, the more errors it contains per 1000 code lines. Look at this wonderful table:
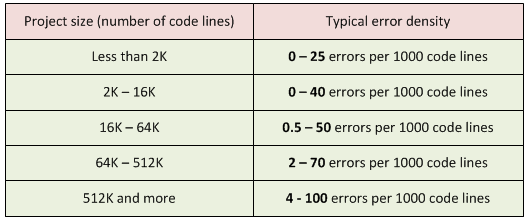
Table 1. Project size and typical error density. The book refers to the following sources: "Program Quality and Programmer Productivity" (Jones, 1977), "Estimating Software Costs" (Jones, 1998).
To make the figures clearer let's draw the diagrams.
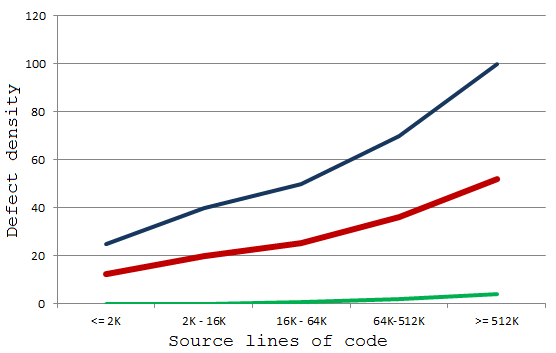
Diagram 1. Typical error density in a project. Blue indicates the maximum number of errors; red - the medium number of errors; green - the minimum number of errors.
Now that you can study these diagrams, you see that the dependency is not a linear one, don't you? The larger a project, the more chances for you to make a mistake in the code.
Of course, static analyzers cannot catch all the errors. But the efficiency of the analyzer grows according to project size. And to make it even more efficient you should use it regularly.
By the way, you may not find any errors at all in a small project. Or there will be just a couple of them. Conclusions you may draw in such a case can be absolutely wrong. That's why I strongly recommend that you try different error detection tools on real working projects.
Yes, it is a harder task, but you will get a proper view of the tool's capabilities. For instance, as one of the PVS-Studio's authors I promise you that we try to help everyone who contacts us. If you have any troubles while trying PVS-Studio, please write to us. Many issues can often be solved by properly setting the tool.
P.S.
I invite you to follow me on Twitter: @Code_Analysis. I regularly post links to interesting articles on the following subjects there: C/C++, static code analysis, optimization and other interesting subjects related to programming.
0
0
0

0