
Our website uses cookies to enhance your browsing experience.

PVS-Studio static analyzer is known in the C, C++, and C# worlds as a tool for detecting errors and potential vulnerabilities. However, we have few clients from the financial sector, because it turned out that now Java and IBM RPG (!) are highly demanded there. As for us, we would like to be closer to the Enterprise world, so after some consideration we decided to start creating Java analyzer.

Sure, we had some concerns. It is quite simple to carve out a niche of IBM RPG analyzers. I am not even sure that there are decent tools for static analysis for this language. In Java world, things are completely different. There is already a range of tools for static analysis, and to get ahead, you need to create a really powerful and cool tool.
Nevertheless, our company had experience of using several tools for static analysis of Java, and we are convinced that many things can be implemented better.
In addition, we had an idea how to tap the full power of our C++ analyzer into the Java analyzer. But first things first.
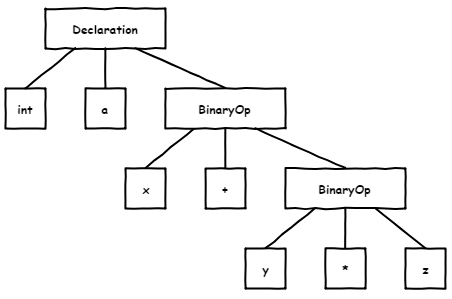
First, it was necessary to decide how we would get a syntax tree and semantic model.
Syntax tree is the base element around which the analyzer is built. When running checks, the analyzer traverses the tree and reviews its separate nodes. It is practically impossible to perform serious static analysis without such a tree. For example, a search for bugs using regular expressions is futile.
It also should be noted that only the syntax tree is not enough. The analyzer requires semantic information as well. For example, we need to know the types of all elements in the tree, be able to jump to a declaration of a variable, etc.
We reviewed several options for obtaining syntax tree and semantic model:
We gave up the idea of using ANTLR almost at once; as it would unreasonably complicate the development of the analyzer (semantic analysis would have been implemented on our own). Eventually we decided to settle on the Spoon library:
Here is an example of a metamodel that Spoon provides, and with which we work when creating diagnostic rules:
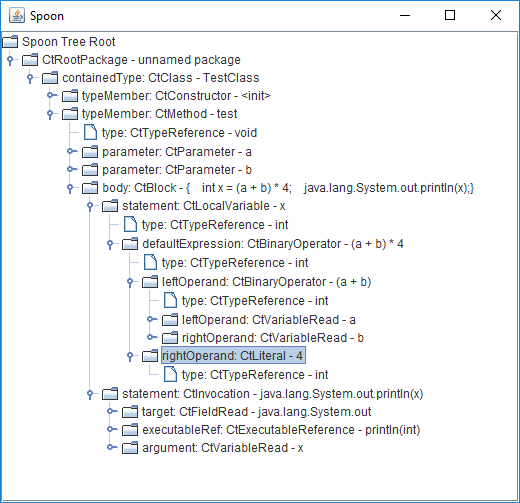
This metamodel corresponds to the following code:
class TestClass
{
void test(int a, int b)
{
int x = (a + b) * 4;
System.out.println(x);
}
}One of the nice features of Spoon is that it simplifies the syntax tree (by removing and adding nodes) to make it easier to work with it. With this, semantic equivalence of a simplified metamodel to a source metamodel is guaranteed.
For us this means, for example, that we do not need to care about skipping the redundant parentheses when traversing the tree. In addition, each expression is placed in the block, imports are expended, and some more similar simplifications are performed.
For example, the following code:
for (int i = ((0)); (i < 10); i++)
if (cond)
return (((42)));will be formatted to the one as follows:
for (int i = 0; i < 10; i++)
{
if (cond)
{
return 42;
}
}Based on syntax tree, a pattern-based analysis is performed. This is a search for errors in the source code of a program by known code patterns containing an error. In the simplest case, the analyzer performs a search in the tree for places, similar to an error, according to the rules described in the appropriate diagnostic. The number of such patterns is large and their complexity can vary greatly.
The simplest example of detectable error using pattern-based analysis is the following code from a jMonkeyEngine project:
if (p.isConnected()) {
log.log(Level.FINE, "Connection closed:{0}.", p);
}
else {
log.log(Level.FINE, "Connection closed:{0}.", p);
}Blocks then and else of the operator if fully coincide. Most likely, there is a logic error.
Here is another similar example from the Hive project:
if (obj instanceof Number) {
// widening conversion
return ((Number) obj).doubleValue();
} else if (obj instanceof HiveDecimal) { // <=
return ((HiveDecimal) obj).doubleValue();
} else if (obj instanceof String) {
return Double.valueOf(obj.toString());
} else if (obj instanceof Timestamp) {
return new TimestampWritable((Timestamp)obj).getDouble();
} else if (obj instanceof HiveDecimal) { // <=
return ((HiveDecimal) obj).doubleValue();
} else if (obj instanceof BigDecimal) {
return ((BigDecimal) obj).doubleValue();
}In this code, there are two identical conditions in a sequence of type if (....) else if (....) else if (....). This code fragment is worth checking for logical error, or the duplicated code should be removed.
In addition to the syntax tree and semantic model, the analyzer requires a mechanism for data flow analysis.
Data flow analysis enables you to calculate the possible values of variables and expressions in each point of the program and, thanks to that, find errors. We call these possible values 'virtual values'.
Virtual values are created for variables, classes' fields, parameters of methods and other things at first reference. If it is the assignment, Data Flow mechanism computes a virtual value by analyzing the expression at the right; otherwise, all the valid range of values for this variable type is taken as a virtual value. For example:
void func(byte x) // x: [-128..127]
{
int y = 5; // y: [5]
...
}At each change of a variable value, Data Flow mechanism recalculates the virtual value. For example:
void func()
{
int x = 5; // x: [5]
x += 7; // x: [12]
...
}Data Flow mechanism also handles control statements:
void func(int x) // x: [-2147483648..2147483647]
{
if (x > 3)
{
// x: [4..2147483647]
if (x < 10)
{
// x: [4..9]
}
}
else
{
// x: [-2147483648..3]
}
...
}In this example, when entering a function, there is no any information about a range of values of the variable x, so the range is set according to the type of a variable (from-2147483648 to 2147483647). Then the first conditional block places a restriction x > 3 and ranges merge. As a result, the range of values for x in then block is as follows: from 4 up to 2147483647 and in the else block is varies from -2147483648 to 3. The second condition x < 10 is handled similarly.
Besides, there has to be the ability to perform purely symbolic computations. The simplest example:
void f1(int a, int b, int c)
{
a = c;
b = c;
if (a == b) // <= always true
....
}Here the variable a is assigned a value c, the variable b is also assigned the value c, then a and b are compared. In this case, to find an error, it is enough to just remember the fragment of the tree that corresponds to the right side.
Here is a slightly more complicated example with symbolic computations:
void f2(int a, int b, int c)
{
if (a < b)
{
if (b < c)
{
if (c < a) // <= always false
....
}
}
}In such cases, we have to do with solving a system of inequalities in a symbolic form.
Data Flow mechanism helps the analyzer to find errors that are quite difficult to detect using a pattern-based analysis.
Such errors include:
Data Flow Analysis is especially important when searching for vulnerabilities. For example, if a certain program receives input from a user, there is a chance that the input will be used to cause a denial of service, or to gain control over the system. Examples may include errors leading to buffer overflows on some data inputs or, for example, SQL injections. In both cases, you need to track data flow and possible values for variables, so that the static analyzer could be able to detect such errors and vulnerabilities.
I should say that the mechanism of Data flow analysis is a complex and extensive mechanism, but in this article, I touched only the basics of it.
Let's see some examples of errors that can be detected using Data Flow mechanism.
Hive project:
public static boolean equal(byte[] arg1, final int start1,
final int len1, byte[] arg2,
final int start2, final int len2) {
if (len1 != len2) { // <=
return false;
}
if (len1 == 0) {
return true;
}
....
if (len1 == len2) { // <=
....
}
}The condition len1 == len2 is always executed, because the opposite check has already been executed above.
Another example from the same project:
if (instances != null) { // <=
Set<String> oldKeys = new HashSet<>(instances.keySet());
if (oldKeys.removeAll(latestKeys)) {
....
}
this.instances.keySet().removeAll(oldKeys);
this.instances.putAll(freshInstances);
} else {
this.instances.putAll(freshInstances); // <=
}Here in the block else null pointer dereference occurs for sure. Note: instances here is the same thing as this.instances.
An example from the JMonkeyEngine project:
public static int convertNewtKey(short key) {
....
if (key >= 0x10000) {
return key - 0x10000;
}
return 0;
}Here the variable key is compared with the number 65536, however, it is of the type short, and the maximum possible value for short is 32767. Accordingly, the condition is never executed.
One more example from the Jenkins project:
public final R getSomeBuildWithWorkspace()
{
int cnt = 0;
for (R b = getLastBuild();
cnt < 5 && b ! = null;
b = b.getPreviousBuild())
{
FilePath ws = b.getWorkspace();
if (ws != null) return b;
}
return null;
}In this code, the variable cnt was introduced to limit the number of steps to five, but a developer forgot to increment it, which resulted in a useless check.
In addition, the analyzer needs a mechanism of annotations. Annotations are a markup system that provides the analyzer with extra information on the used methods and classes in addition to the data that can be obtained by the analysis of their signatures. Markup is done manually; this is a long and time-consuming process, because to achieve the best results one has to annotate a large number of standard Java classes and methods. It also makes sense to perform annotation of popular libraries. Overall, annotations can be regarded as a knowledge base of the analyzer about contracts of standard methods and classes.
Here's a small sample of an error that can be detected by using annotations:
int test(int a, int b) {
...
return Math.max(a, a);
}In this example, the same variable (passed as a first argument) was passed as the second argument of the method Math.max because of a typo. Such an expression is meaningless and suspicious.
Static analyzer may issue a warning for such code, as it's aware of the fact that arguments of the method Math.max always have to be different.
Going forward, here are a few examples of our markup of built-in classes and methods (code in C++):
Class("java.lang.Math")
- Function("abs", Type::Int32)
.Pure()
.Set(FunctionClassification::NoDiscard)
.Returns(Arg1, [](const Int &v)
{ return v.Abs(); })
- Function("max", Type::Int32, Type::Int32)
.Pure()
.Set(FunctionClassification::NoDiscard)
.Requires(NotEquals(Arg1, Arg2)
.Returns(Arg1, Arg2, [](const Int &v1, const Int &v2)
{ return v1.Max(v2); })
Class("java.lang.String", TypeClassification::String)
- Function("split", Type::Pointer)
.Pure()
.Set(FunctionClassification::NoDiscard)
.Requires(NotNull(Arg1))
.Returns(Ptr(NotNullPointer))
Class("java.lang.Object")
- Function("equals", Type::Pointer)
.Pure()
.Set(FunctionClassification::NoDiscard)
.Requires(NotEquals(This, Arg1))
Class("java.lang.System")
- Function("exit", Type::Int32)
.Set(FunctionClassification::NoReturn)Explanations:
It is worth noting that, in addition to manual markup, there is another approach to annotating, which is an automatic inference of contracts based on bytecode. It is clear that such an approach allows to obtain only certain types of contracts, but, however, it enables to receive additional information from all dependencies, not just from those that were annotated manually.
By the way, there is already a tool that is able to infer the contracts like @Nullable, @NotNull based on bytecode - FABA. As far as I understand, the derivative of the FABA is used in IntelliJ IDEA.
At the moment, we are also considering the ability to add the bytecode analysis for obtaining contracts of all methods, as these contracts could well complement our manual annotations.
Diagnostic rules often refer to the annotations. In addition to diagnostics, annotations are used by the Data Flow mechanism. For example, using the annotation method java.lang.Math.abs, it can accurately calculate the absolute value of a number. And we don't have to write any additional code for that, we only need to correctly annotate a method.
Let's consider the example of an error which can be found due to annotations from the Hibernate project:
public boolean equals(Object other) {
if (other instanceof Id) {
Id that = (Id) other;
return purchaseSequence.equals(this.purchaseSequence) &&
that.purchaseNumber == this.purchaseNumber;
}
else {
return false;
}
}In this code, the method equals() compares the object purchaseSequence with itself. Most likely, this is a typo and that.purchaseSequence should be written on the right, but not purchaseSequence.
Since Data Flow and annotation mechanisms themselves are not strongly tied to a specific language, it was decided to re-use these mechanisms from our C++ analyzer. This lets us obtain the whole power of the C++ analyzer in our Java analyzer within a short time. In addition, this decision was also influenced by the fact that these mechanisms were written in modern C++ with a bunch of metaprogramming and template magic, and therefore these solutions are not very suitable for porting into another language.
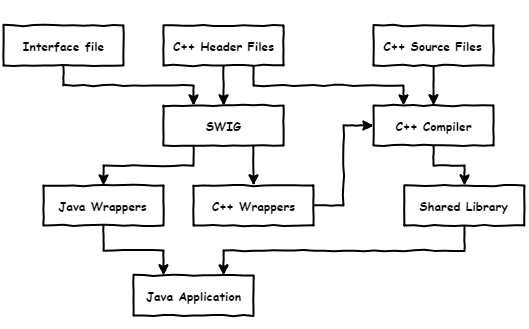
In order to connect the Java part with the C++ kernel, we decided to use SWIG (Simplified Wrapper and Interface Generator) which is a tool for automatic generation of wrappers and interfaces for bounding C and C++ programs, with programs, written in other languages. SWIG generates code in JNI (Java Native Interface) for Java.
SWIG is great for cases when there is already a large amount of C++ code that needs to be integrated in a Java project.
Let me give you a small example of working with SWIG. Let's suppose we have a C++ class that we want to use in a Java project:
CoolClass.h
class CoolClass
{
public:
int val;
CoolClass(int val);
void printMe();
};CoolClass.cpp
#include <iostream>
#include "CoolClass.h"
CoolClass::CoolClass(int v) : val(v) {}
void CoolClass::printMe()
{
std::cout << "val: " << val << '\n';
}You must first create a SWIG interface file with a description of all the exported functions and classes. Also, perform additional settings in this file, if necessary.
Example.i
%module MyModule
%{
#include "CoolClass.h"
%}
%include "CoolClass.h"After that, you can run SWIG:
$ swig -c++ -java Example.iIt will generate the following files:
Now you just need to add the resultant .java files in the Java project and the .cxx file in the C++ project.
Finally, you need to compile the C++ project as a DLL and load it in the Java project using System.loadLibary():
App.java
class App {
static {
System.loadLibary("example");
}
public static void main(String[] args) {
CoolClass obj = new CoolClass(42);
obj.printMe();
}
}Schematically, this can be represented as follows:
Sure, in a real project, things are not that simple and you have to upscale efforts:
You can learn more about all of these mechanisms in the SWIG documentation.
Our analyzer is built using gradle, which calls CMake, which, in turns, calls SWIG and builds the C++ part. For programmers it happens almost imperceptibly, so we experience no particular inconvenience when developing.
The core of our C++ analyzer is built under Windows, Linux and macOS, so the Java analyzer also works in these operating systems.
We write diagnostics themselves and code for analysis in Java. It is stemmed from the close interaction with the Spoon. Each diagnostic rule represents a visitor with overloaded methods in which the elements interesting for us are traversed:
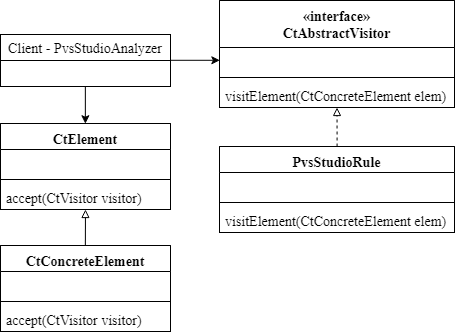
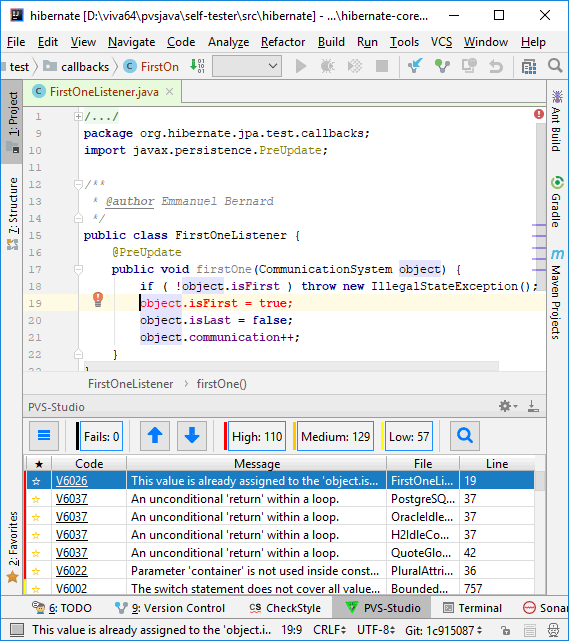
For example, this is how a V6004 diagnostic frame looks like:
class V6004 extends PvsStudioRule
{
....
@Override
public void visitCtIf(CtIf ifElement)
{
// if ifElement.thenStatement statement is equivalent to
// ifElement.elseStatement statement => add warning V6004
}
}For simple static analyzer integration in the project, we've developed plugins for build systems Maven and Gradle. A user just needs to add our plugin to the project.
For Gradle:
....
apply plugin: com.pvsstudio.PvsStudioGradlePlugin
pvsstudio {
outputFile = 'path/to/output.json'
....
}For Maven:
....
<plugin>
<groupId>com.pvsstudio</groupId>
<artifactId>pvsstudio-maven-plugin</artifactId>
<version>0.1</version>
<configuration>
<analyzer>
<outputFile>path/to/output.json</outputFile>
....
</analyzer>
</configuration>
</plugin>After that, the plugin itself will receive the project structure and start the analysis.
In addition, we have developed a plugin prototype for IntelliJ IDEA.
In addition, this plugin works in Android Studio.
Plugin for Eclipse is now under development.
We have provided the incremental analysis mode that allows checking only modified files, which significantly reduces the time for analysis. Thanks to that, developers will be able to run the analysis as often as necessary.
Incremental analysis involves several stages:
To test the Java analyzer on real projects we wrote special tools to work with the database of open source projects. It was written in Python + Tkinter and is cross-platform.
It works in the following way:
Such approach ensures that good warnings will not disappear because of changes in the analyzer code. The following illustration shows the interface of our utility for testing.
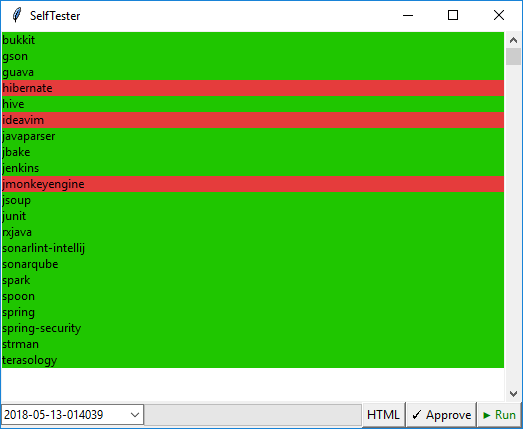
Red highlights are the projects, whose reports have differences with the etalon. The Approve button allows saving the current version of the report as an etalon.
By tradition, I will demonstrate several errors from different open source projects that our Java analyzer has detected. In the future, we plan to write articles with a more detailed report on each project.
PVS-Studio warning: V6009 Function 'equals' receives odd arguments. Inspect arguments: this, 1. PurchaseRecord.java 57
public boolean equals(Object other) {
if (other instanceof Id) {
Id that = (Id) other;
return purchaseSequence.equals(this.purchaseSequence) &&
that.purchaseNumber == this.purchaseNumber;
}
else {
return false;
}
}In this code, the method equals() compares the object purchaseSequence with itself. Most likely, this is a typo and that.purchaseSequence, not purchaseSequence should be written on the right.
PVS-Studio warning: V6009 Function 'equals' receives odd arguments. Inspect arguments: this, 1. ListHashcodeChangeTest.java 232
public void removeBook(String title) {
for( Iterator<Book> it = books.iterator(); it.hasNext(); ) {
Book book = it.next();
if ( title.equals( title ) ) {
it.remove();
}
}
}A triggering, similar to the previous one - book.title, not title has to be on the right.
PVS-Studio warning: V6007 Expression 'colOrScalar1.equals("Column")' is always false. GenVectorCode.java 2768
PVS-Studio warning: V6007 Expression 'colOrScalar1.equals("Scalar")' is always false. GenVectorCode.java 2774
PVS-Studio warning: V6007 Expression 'colOrScalar1.equals("Column")' is always false. GenVectorCode.java 2785
String colOrScalar1 = tdesc[4];
....
if (colOrScalar1.equals("Col") &&
colOrScalar1.equals("Column")) {
....
} else if (colOrScalar1.equals("Col") &&
colOrScalar1.equals("Scalar")) {
....
} else if (colOrScalar1.equals("Scalar") &&
colOrScalar1.equals("Column")) {
....
}Here the operators were obviously confused and '&&' was used instead of '||'.
PVS-Studio warning: V6001 There are identical sub-expressions 'tokenRange.getBegin().getRange().isPresent()' to the left and to the right of the '&&' operator. Node.java 213
public Node setTokenRange(TokenRange tokenRange)
{
this.tokenRange = tokenRange;
if (tokenRange == null ||
!(tokenRange.getBegin().getRange().isPresent() &&
tokenRange.getBegin().getRange().isPresent()))
{
range = null;
}
else
{
range = new Range(
tokenRange.getBegin().getRange().get().begin,
tokenRange.getEnd().getRange().get().end);
}
return this;
}The analyzer has detected that on the left and the right of the operator && there are identical expressions (besides that, all methods in the chain are pure). Most likely, in the second case, tokenRange.getEnd() has to be used rather than tokenRange.getBegin().
PVS-Studio warning: V6016 Suspicious access to element of 'typeDeclaration.getTypeParameters()' object by a constant index inside a loop. ResolvedReferenceType.java 265
if (!isRawType()) {
for (int i=0; i<typeDeclaration.getTypeParams().size(); i++) {
typeParametersMap.add(
new Pair<>(typeDeclaration.getTypeParams().get(0),
typeParametersValues().get(i)));
}
}The analyzer has detected a suspicious access to the element of a collection by constant index inside the loop. Perhaps there is an error in this code.
PVS-Studio warning: V6007 Expression 'cnt < 5' is always true. AbstractProject.java 557
public final R getSomeBuildWithWorkspace()
{
int cnt = 0;
for (R b = getLastBuild();
cnt < 5 && b ! = null;
b = b.getPreviousBuild())
{
FilePath ws = b.getWorkspace();
if (ws != null) return b;
}
return null;
}In this code, the variable cnt was introduced to limit the number of traverses to five, but a developer forgot to increment it, which resulted in a useless check.
PVS-Studio warning: V6007 Expression 'sparkApplications != null' is always true. SparkFilter.java 127
if (StringUtils.isNotBlank(applications))
{
final String[] sparkApplications = applications.split(",");
if (sparkApplications != null && sparkApplications.length > 0)
{
...
}
}Check of the result, returned by the split method, for null is meaningless, because this method always returns a collection and never returns null.
PVS-Studio warning: V6001 There are identical sub-expressions '!m.getSimpleName().startsWith("set")' to the left and to the right of the '&&' operator. SpoonTestHelpers.java 108
if (!m.getSimpleName().startsWith("set") &&
!m.getSimpleName().startsWith("set")) {
continue;
}In this code, there are identical expressions on the left and right of the && operator (in addition to that, all methods in the chain are pure). Most likely, there is a logic error in the code.
PVS-Studio warning: V6007 Expression 'idxOfScopeBoundTypeParam >= 0' is always true. MethodTypingContext.java 243
private boolean
isSameMethodFormalTypeParameter(....) {
....
int idxOfScopeBoundTypeParam = getIndexOfTypeParam(....);
if (idxOfScopeBoundTypeParam >= 0) { // <=
int idxOfSuperBoundTypeParam = getIndexOfTypeParam(....);
if (idxOfScopeBoundTypeParam >= 0) { // <=
return idxOfScopeBoundTypeParam == idxOfSuperBoundTypeParam;
}
}
....
}Here the author of the code made a typo and wrote idxOfScopeBoundTypeParam instead of idxOfSuperBoundTypeParam.
PVS-Studio warning: V6001 There are identical sub-expressions to the left and to the right of the '||' operator. Check lines: 38, 39. AnyRequestMatcher.java 38
@Override
@SuppressWarnings("deprecation")
public boolean equals(Object obj) {
return obj instanceof AnyRequestMatcher ||
obj instanceof security.web.util.matcher.AnyRequestMatcher;
}The triggering is similar to the previous one - the name of the same class is written in different ways.
PVS-Studio warning: V6006 The object was created but it is not being used. The 'throw' keyword could be missing. DigestAuthenticationFilter.java 434
if (!expectedNonceSignature.equals(nonceTokens[1])) {
new BadCredentialsException(
DigestAuthenticationFilter.this.messages
.getMessage("DigestAuthenticationFilter.nonceCompromised",
new Object[] { nonceAsPlainText },
"Nonce token compromised {0}"));
}In this code, a developer forgot to add the throw before the exception. As a result, the object of the exception BadCredentialsException is created, but is not used, i.e., no exception is thrown.
PVS-Studio warning: V6030 The method located to the right of the '|' operators will be called regardless of the value of the left operand. Perhaps, it is better to use '||'. RedirectUrlBuilder.java 38
public void setScheme(String scheme) {
if (!("http".equals(scheme) | "https".equals(scheme))) {
throw new IllegalArgumentException("...");
}
this.scheme = scheme;
}In this code, the usage of the operator | is undue, because when the right part will be calculated, even if the left part is already true. In this case, it has no practical meaning, so the operator | has to be replaced with ||.
PVS-Studio warning: V6008 Potential null dereference of 'editor'. IntroduceVariableBase.java:609
final PsiElement nameSuggestionContext =
editor == null ? null : file.findElementAt(...); // <=
final RefactoringSupportProvider supportProvider =
LanguageRefactoringSupport.INSTANCE.forLanguage(...);
final boolean isInplaceAvailableOnDataContext =
supportProvider != null &&
editor.getSettings().isVariableInplaceRenameEnabled() && // <=
...The analyzer has detected that in this code a dereference of a null pointer editor may occur. It is necessary to add additional check.
PVS-Studio warning: V6007 Expression is always false. RefResolveServiceImpl.java:814
@Override
public boolean contains(@NotNull VirtualFile file) {
....
return false & !myProjectFileIndex.isUnderSourceRootOfType(....);
}It is difficult for me to say what the author had in mind, but this looks very suspicious. Even if there is no error here, this place should be rewritten to not to confuse the analyzer and other programmers.
PVS-Studio warning: V6007 Expression 'result[0]' is always false. CopyClassesHandler.java:298
final boolean[] result = new boolean[] {false}; // <=
Runnable command = () -> {
PsiDirectory target;
if (targetDirectory instanceof PsiDirectory) {
target = (PsiDirectory)targetDirectory;
} else {
target = WriteAction.compute(() ->
((MoveDestination)targetDirectory).getTargetDirectory(
defaultTargetDirectory));
}
try {
Collection<PsiFile> files =
doCopyClasses(classes, map, copyClassName, target, project);
if (files != null) {
if (openInEditor) {
for (PsiFile file : files) {
CopyHandler.updateSelectionInActiveProjectView(
file,
project,
selectInActivePanel);
}
EditorHelper.openFilesInEditor(
files.toArray(PsiFile.EMPTY_ARRAY));
}
}
}
catch (IncorrectOperationException ex) {
Messages.showMessageDialog(project,
ex.getMessage(),
RefactoringBundle.message("error.title"),
Messages.getErrorIcon());
}
};
CommandProcessor processor = CommandProcessor.getInstance();
processor.executeCommand(project, command, commandName, null);
if (result[0]) { // <=
ToolWindowManager.getInstance(project).invokeLater(() ->
ToolWindowManager.getInstance(project)
.activateEditorComponent());
}I suspect that here one forgot to somehow change the value in result. Because of this, the analyzer reports that the check if (result[0]) is meaningless.
Java development is very versatile. It includes desktop, android, web and much more, so we have plenty of room for activities. First and foremost, of course, we will develop the areas that are most in demand.
Here are our plans for the near future:
Also I'd like to suggest readers taking part in testing alfa-version of our Java analyzer when it becomes available. For this, write to our support. We'll add your contacts to our list and will write you, when the first alfa-version is ready.
0
0
0

0