
Our website uses cookies to enhance your browsing experience.

I decided to find out if there is practical sense in writing ++iterator instead of iterator++, when handling iterators. My interest in this question arose not from my love of art, but practical reasons. We have intended for a long time to develop PVS-Studio not only in the direction of error searching, but in the direction of prompting tips on code optimization. A message telling you that you'd be better off write ++iterator, is quite suitable in the scope of optimization.
But how relevant is this recommendation nowadays? In ancient times, for instance, it was advised not to repeat calculations. It was a good manner to write:
TMP = A + 10;
X = TMP + B;
Y = TMP + C;instead of
X = A + 10 + B;
Y = A + 10 + C;Such subtle manual optimization is meaningless now. The compiler would handle this task as well. It's just unnecessary complication of code.
Note for the pedantic ones. Yes, you'd better not repeat calculations and calculate long expressions, which are used several times, separately. What I'm talking about is that there is no reason in optimizing simple cases like the one I have mentioned.
Well, we have digressed from our main point, which is the question of whether the advice to use the prefix increment instead of postfix increment for iterators is obsolete nowadays; if we should store in our mind one more subtle thing. Perhaps the compiler learned to optimize prefix increments long ago.
A bit of theory first, for those who are not familiar with the topic. All the rest may scroll down the text a bit.
The prefix increment operator changes an object's state and returns itself in the changed form. The prefix increment operator in the iterator class to handle std::vector may look like this:
_Myt& operator++()
{ // preincrement
++_Myptr;
return (*this);
}The situation with the postfix increment is more complicated. The object's state must change, but it is the previous state which is returned. An additional temporary object is created:
_Myt operator++(int)
{ // postincrement
_Myt _Tmp = *this;
++*this;
return (_Tmp);
}If we want to increment only the iterator's value, it turns out that the prefix operator is preferable. That is why, here we have one of the tips concerning software micro-optimization: write for (it = a.begin(); it != a.end; ++it) instead of for (it = a.begin(); it != a.end; it++). In the latter case, an unnecessary temporary object is created, which reduces performance.
You may read about all this in detail in the book by Scott Meyers "Efficient use of C++. 35 new recommendations on improving your programs and projects" (Rule 6. Distinguish between prefix increment and decrement operators) [1].
The theory is over. Now practice. Is there sense in replacing the postfix increment with the prefix one in code?
size_t Foo(const std::vector<size_t> &arr)
{
size_t sum = 0;
std::vector<size_t>::const_iterator it;
for (it = arr.begin(); it != arr.end(); it++)
sum += *it;
return sum;
}I know that we may wander into the depths of philosophy now. Say, it may turn out that some other class would become the container instead of vector and iterators in this new class would be very complex and heavy; when copying the iterator, we would have to establish a new connection to the database and so on. So, you must always write ++it.
But this is theory; in practice, when we encounter such a loop in our code, is it reasonable to replace it++ with ++it? Can we not rely on the fact that the compiler will guess itself, that it can throw away an unnecessary iterator?
The answers are strange, but the reason why we give them will become evident through further experimentation.
Yes, we must replace it++ with ++it.
Yes, the compiler will optimize the code and it won't matter what increment we use.
I chose an "average compiler", and created a test project for Visual Studio 2008. It has two functions which calculate the sum using it++ and ++it and also estimates their running time. You may download the project here. Here is the code of functions, the speed of which was measured:
1) Postfix increment. iterator++.
std::vector<size_t>::const_iterator it;
for (it = arr.begin(); it != arr.end(); it++)
sum += *it;2) Prefix increment. ++iterator.
std::vector<size_t>::const_iterator it;
for (it = arr.begin(); it != arr.end(); ++it)
sum += *it;Working time in the Release version:
iterator++. Total time : 0.87779
++iterator. Total time : 0.87753This is the answer to the question of whether the compiler can optimize the postfix increment. Sure it can. If you study the implementation (assembler code), you will see that both functions are implemented with the same instruction set.
Now let's answer the question, "Why should we replace it++ with ++it then?" Let's measure the speed of functions in the Debug version:
iterator++. Total time : 83.2849
++iterator. Total time : 27.1557There is practical sense in writing the code so that it only slows down 30 times, and not 90 times.
Of course, the speed of the Debug versions is not really crucial for many programmers. But if a program does something for a long time, such a large slow-down might very well be crucial; for instance, from the viewpoint of unit-tests. So, it is reasonable to optimize the speed of the Debug version.
I carried out one more experiment, to find out what I would get using the good old size_t for indexing. I know it doesn't relate to the topic we are discussing, and I understand that we cannot compare iterators with indexes, and that the former are higher-level entities. But still I wrote, and measured the speed of the following functions just out of curiosity:
1) Classic index of the size_t type. i++.
for (size_t i = 0; i != arr.size(); i++)
sum += arr[i];2) Classic index of the size_t type. ++i.
for (size_t i = 0; i != arr.size(); ++i)
sum += arr[i];The speed in the Release version:
iterator++. Total time : 0.18923
++iterator. Total time : 0.18913The speed in the Debug version:
iterator++. Total time : 2.1519
++iterator. Total time : 2.1493As we had expected, the speeds of i++ and ++i coincided.
Note. Code with size_t works faster in comparison to iterators due to absence of array overrun check. We can make the loop with iterators as fast in the Release version by adding the line #define _SECURE_SCL 0.
To make it easier for you to evaluate the results of the speed measurements, I have presented them in a table (Figure 1). I have converted the results, taking the running time of Release version with iterator++ for a unit. I also rounded them off a bit to make them clearer.
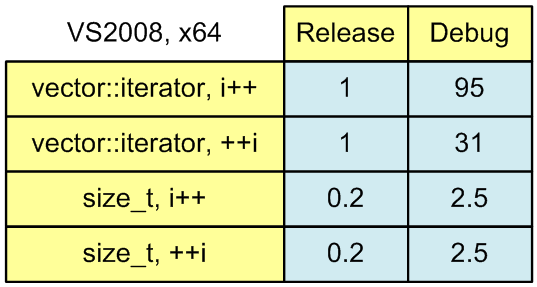
Figure 1. The running time of sum calculation algorithms.
Each one of you can draw your own conclusions. They depend upon tasks you are solving. Personally I came to the following conclusions:
P.S.:
Someone will say now that untimely optimization is evil [2]; when you need optimization, you take the profiler, and search for bottlenecks. I know this. And I got rid of certain bottlenecks long ago. But when I'm waiting for the tests to finish for 4 hours, I start thinking that it is a very good idea to gain at least 20% speed. Such optimization is comprised of iterators, structure sizes, avoiding using STL or Boost in some fragments, and so on. I believe that some developers agree with me.
0
0
0

0